|
|
You are here: NRAO Public Wiki>Main Web>TWikiUsers>JoeBrandt>GPUClusterDescription (2007-10-27, JoeBrandt)
Edit wiki text
Edit
Attach
Print version
Green Bank GPU Cluster Description
This page describes a GPU cluster currently being assembled to test the application of GPU technology for backend data processing.Introduction
Over the past ten years or so, CPU chip vendors have doubled CPU performance approximately every 18 months. This is described as 'Moores Law'. This progression remained linear for quite some time, but in recent years it has been recognized that single core performance has its limits. Today, multi-core CPU chipsets are common. Where do Graphics Processing Units (GPU) factor in? Well first it should be stated that the process of drawing three dimensional scenes is a very parallel problem. The gaming industry has recognized this for some time and has been developing hardware to fill a huge demand for 'gaming hardware'. Fortunately this commodity development has opened a door toward high-performance computing for areas where the problem set lends itself to a parallel solution. The Nvidia corporation manufactures the G80 processor, which contains 128 SPMD (single program-multiple data) processing elements. Cards which host this processor are available as the GTX8800, sold by a number of vendors, such as BFG, EVGA, and XFX. Similarly powerful cards are available from ATI, Nvidia's main competitor.Hardware
The cluster consists of four identical nodes. Each node hosts two GTX8800 cards, 1TB of disk, 4GB RAM, and an Intel Quad core processor. Communications are via two 1GBit Ethernet links. Using marketing style numbers, the aggregate GPU computing power should be on the order of 4x1012 floating point operations per second (4 Tera-FLOPS). Realistic numbers are probably around half to one quarter of this figure, however even that level of performance is still rather impressive. The diagram below outlines the cluster arrangement: 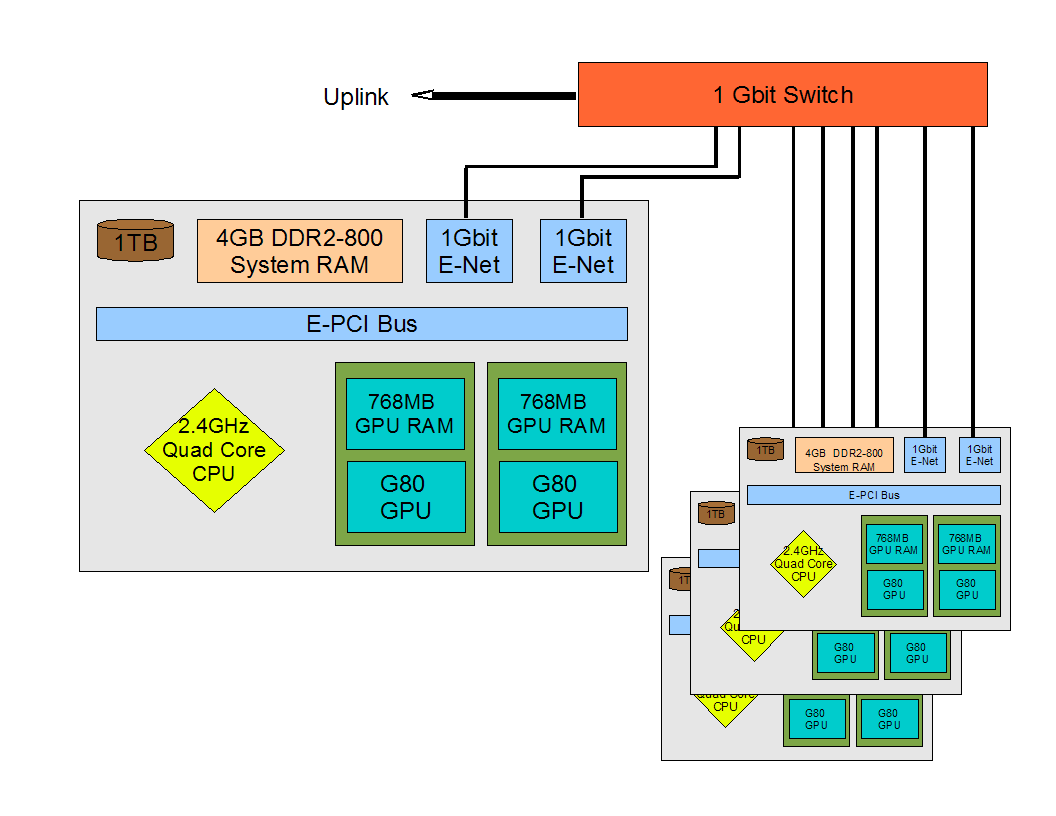 |
| A schematic of the cluster |
| CPU | One Quad Core 2.4GHz, 2x4MB cache |
| RAM | 4G Bytes |
| Motherboard | ASUS P5N-32 SLI Plus (nVidia 680 Chipset) |
| Disk | Dual 500GB, 3Gbit/sec-SATA |
| LAN | Dual 10/100/1000 Ethernet |
| GPU | Dual eVGA 8800GTX Ultra |
| PSU | 1000W SLI Certified |
| An annotated picture of our first node: |
 |
Software
Processing Model
A number of languages are available for GPU's: Brooke (Stanford University); Cg (Nvidia); CUDA(from Nvidia); HLSL (Microsoft); and PeakStream (PeakStream Inc.). Each environment has its own advantages. For our use we are concentrating on CUDA, since it seems most flexible for our use. The CUDA processing model concentrates on a large number of parallel threads. The theads are organized in groups of threads which can share data is shared memory, called blocks. Blocks of threads are further organized into a matrix called a Grid. This geometrical organization is useful, because each thread must determine what portion of the data to operate upon. This self-identification is a convenient way to coordinate processing amongst threads. To exploit parallelism, the dependencies between data must be identified, and processing localized. This sometimes requires a re-casting of the problem in a non-traditional way.Operating System
Similar to many other clusters, Linux is the OS of choice. We currently run Redhat SMP linux Enterprise 4.OS Tweaks Required on 32-bit Kernels
After powering up the cluster with Redhat Linux (RHEL-4), I found that CUDA was unable to recognize either card. It turns out that a 32-bit kernel has some limitations with respect to virtual address space. With 4GB's of RAM, (896MB of low memory) there isn't enough kernel virtual address space to map the hardware! (A 64bit kernel wouldn't have this problem of course.) Fortunately there is a solution. By the addition of some incantations into the /boot/grub/grub.conf file, we can inactivate a little bit of RAM in low memory, in exchange for some virtual address space for mapping the cards. The modified grub entry looks like (added items in bold):-
title Red Hat Enterprise Linux AS (2.6.9-55.0.9.ELsmp Dual GPU)
root (hd0,0)
uppermem 524288
kernel /boot/vmlinuz-2.6.9-55.0.9.ELsmp ro root=LABEL=/ selinux=0 vmalloc=256MB pci=nommconf
initrd /boot/initrd-2.6.9-55.0.9.ELsmp.img
Monitoring
As a quick start to monitor some key parameters, I installed the Ganglia package. This is fine for host related items, but I feel a strong need to monitor GPU temperature. The addition of this is easy if and only if I can find a way to read the temperature. (Current methods require a connection to an xserver, but I don't plan on having one running.) Publishing the temperature is straight forward using the gmetrics utility.GPU Programming Language/Environment
The two main programming languages for general purpose applications on nVidia GPUs are:- CUDA (supported by nVidia)
- Brook (From the BrookGPU project)
Clustering Package
There are a number of choices, but Open MPI seems to work well. Other options have not yet been evaluated.- Open MPI
Network
Nothing spectacular here (yet). Currently each node connects into a switch with a single 1 Gbit Ethernet link. There are two 1 Gbit links available per system, and one system will have an additional 10 Gbit card.Performance
Since the cluster is not yet fully operational, performance data is not yet available. However, Paul Demorest has done an excellent page, examining GPU use for pulsar data analysis.Possible Applications
So what nail can be hit with this huge sledge hammer? Possible candidate applications may include:- Beam forming
- GASP Augmentation
- RFI Applications
- Pulsar data processing
Power/Cooling
With a typical idling temperature of around 65C, cooling a number of dual GPU systems can be a challenge. Monitoring GPU temperatures during extended processing is a must. On the question of power, I estimate the following (based on past experience and recent measurements of GPU current):| 340W | (2 GPU's) |
| 110W | CPU |
| 75W | N/S Chipsets |
| 50W | Memory |
| 50W | Misc. |
| 625W/780W | (625W at 80% efficiency) per node |


| I | Attachment | Action | Size | Date | Who |
Comment |
|---|---|---|---|---|---|---|
| |
firstnode.JPG | manage | 618 K | 2007-09-12 - 20:07 | JoeBrandt | Photo of our first assembled node |
| |
gpucluster.png | manage | 2 MB | 2007-09-16 - 18:46 | JoeBrandt |
Edit | Attach | Print version | History: r5 < r4 < r3 < r2 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r4 - 2007-10-27, JoeBrandt


 - NRAO Public Wiki
- NRAO Public Wiki
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding NRAO Public Wiki? Send feedback